Quantum Computing
Quantum Benchmarketing For Quantum Computers
This article was originally published on the ClassIQ's Blog on 2 November, 2023.
Quantum computing promises to revolutionize some industries, like materials, medicine, and finance. Yet, the question remains: When will these quantum computers be good enough to actually solve a real-life problem?
Those hype-driven press releases that tell you “We have released a new quantum system with one million qubits!” don’t tell you the whole story. A million qubits with very high error and low coherence (the length of time quantum states are stored) are not as useful as 100 ideal qubits – we’d all rather have the latter any day.
But how do we determine the effectiveness and performance of these quantum machines? It’s not as easy as classical computers. The widely accepted SPEC benchmarks measure different aspects of computer performance, including CPU tasks like integer and floating-point arithmetic, memory and storage capabilities, system-level operations like multi-threading, and application-specific tasks such as database queries and web server throughput. These benchmarks provide a standardized way to compare different hardware and software configurations.
Some new aggregate single-number metrics, like the IBM-led Quantum Volume, incorporate factors like gate and measurement errors, crosstalk, and connectivity. But there are still parameters missing. Even gate operation times are often missing from technical documentation. Just as traditional computers undergo performance and stress tests to show their capabilities, benchmarking is critical for quantum computers to show their impact.
What is Benchmarking?
Benchmarking, in the simplest terms, is the process of comparing the performance of a system against a standard or performance of similar systems. For quantum computers, technical benchmarking measures fidelities, calculation success, statistics, or other noise measures for specific sets of gates (the building blocks of quantum circuits) and qubits.
When benchmarking a device, we understand its strengths, weaknesses, areas for improvement, and understanding of the system's capabilities. For example, comparing a CPU to a GPU will show the CPU winning for systems operations and typical computer use, but training a deep learning model or mining Bitcoin on a GPU will blow that CPU out of the water.
What Should Quantum Benchmarking Do?
Quantum benchmarking should give us a detailed understanding of the system’s capabilities:
- Ensure Accuracy: Unlike classical bits, quantum bits (qubits) can exist in a superposition of states, which makes them inherently probabilistic. This means that running the same quantum algorithm multiple times might yield different results. Benchmarking helps determine the reliability of a quantum computer by testing how often it returns the correct answer.
- Gauge Performance Metrics: Quantum computers are expected to solve problems too complex for classical computers. Benchmarking can determine how much faster or even more energy-efficiently a quantum computer can solve a problem compared to a classical supercomputer.
- Establish Error Rates: Quantum systems are sensitive to external influences, leading to much higher errors in gate operations and coherence. Benchmarking helps error rates, a vital statistic in understanding a system's reliability. However, the key is that error rates may drift over time, and quantum computers are often recalibrated. The benchmarking rates may not be accurate for long.
- Validate Quantum Supremacy: Quantum supremacy is where quantum computers can solve problems that classical computers can’t.
Types of Quantum Benchmarking
Given the early stage of the technology, determining a quantum computer's capability isn't as straightforward as measuring the speed of a classical computer, nor is it standardized. Quantum benchmarking is broken down into various types, each serving a specific purpose in gauging the performance characteristics of a quantum device.
Here are some of the key types of quantum benchmarking:
Randomized Benchmarking
One of the most common baseline techniques is randomized benchmarking. This method helps to measure the average error rates of quantum gates in a quantum processor. By applying a series of random quantum gates and then measuring the outcomes, randomized benchmarking creates an error rate estimate generally insensitive to state preparation and measurement errors.
Gate Set Tomography
Gate set tomography emerged around 2012, and has since been refined and used in a large number of experiments to overcome issues in randomized benchmarking. Gate set tomography provides a complete characterization of the logical operations that a quantum processor can perform, including systematic errors. The method requires significantly more resources than randomized benchmarking but outputs a detailed error model of the quantum gate set.
Quantum Process Tomography
Quantum process tomography is used to reconstruct the behavior of a quantum process or gate by preparing different input states, applying the quantum process, and then measuring the output states. While this technique can be very accurate for small numbers of qubits, it too becomes difficult and resource-intensive for multi-qubit systems.
Quantum State Tomography
Quantum state tomography is similar to quantum process tomography but focuses on characterizing quantum states rather than processes. It is also resource-intensive and becomes challenging as the number of qubits increases.
Crosstalk Benchmarking
Crosstalk is an issue in bigger quantum systems where gate operations on one qubit affect the other. Randomized benchmarking can’t capture this information, so crosstalk benchmarking measures these unwanted interactions. This measure becomes important for algorithms that need to parallelize quantum gates.
Cycle Benchmarking
Cycle benchmarking is a newer technique designed to measure the error of an entire cycle (or layer) of quantum gates, as opposed to individual gates, and captures errors arising from cross-talk between qubits and other local and global errors across multi-qubit processors.
Cross-Entropy Benchmarking
Cross-entropy benchmarking (XEB) is used to evaluate the performance of quantum processors by comparing the output distribution of a quantum circuit to an ideal or target distribution. The output metric calculates the accuracy of quantum gates and the fidelity of quantum computations and compares how closely a quantum processor approximates ideal quantum operations. Google’s Sycamore Processor used XEB to demonstrate their claims of quantum supremacy.
Each of these types of benchmarking has its own advantages and weaknesses, and they are often combined to understand the full picture of a quantum processor's capabilities. As the types of quantum hardware and capabilities of these systems grow, new methods of quantum benchmarking will likely be proposed.
Trust, But Verify: Your Benchmarking Challenge
Let’s say a new quantum chip is released and there are extraordinary claims as to the power of the device. Even if benchmarking statistics aren’t published, or the calibration statistics are old, you can run benchmarking code independently. Classiq provides a one-stop platform to run benchmarking tests on your own, on a large set of real quantum hardware systems from different vendors and simulators for idealized comparisons.
Your task is to use Classiq’s platform to run a randomized benchmarking experiment on various quantum hardware and compare it with a simulator. To get started with the Classiq Python SDK, follow the instructions here.
The given code is a Python example that uses the Classiq library to perform randomized benchmarking and compares two-qubit Clifford fidelity on IBM's "Nairobi" device and the IBM Aer “ideal” quantum simulator.
The full code can be found here.
Importing Libraries
This block imports various libraries and modules needed for the program. Libraries like asyncio and itertools are standard Python libraries, while the classiq library provides the functions and classes for quantum computing extensions.
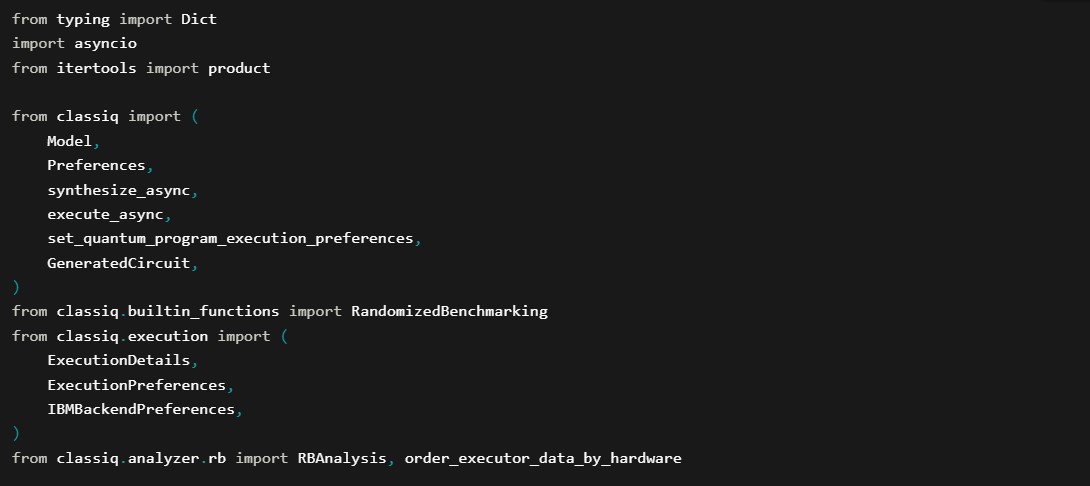
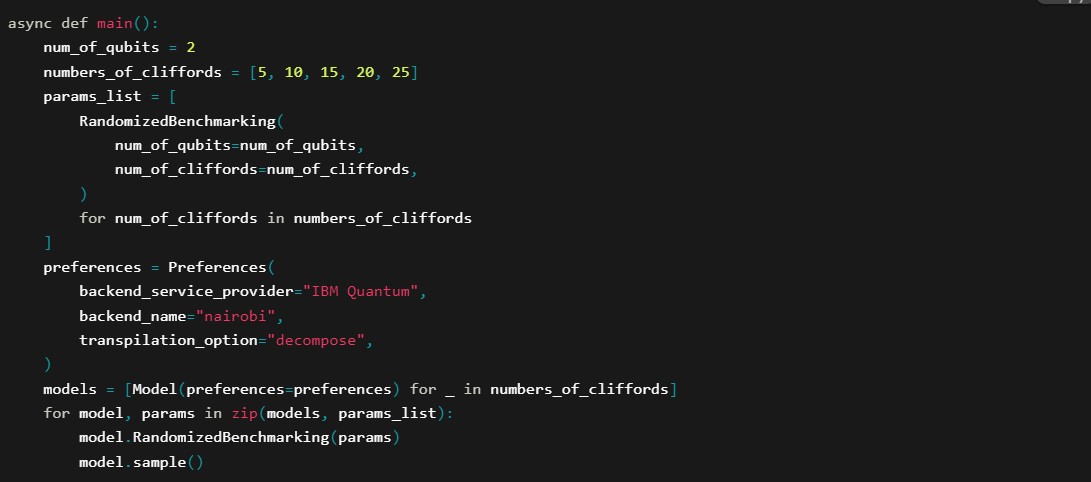
Asynchronous Main Function
Here, we set the preferences for which quantum computer backend to use (IBM Quantum and its nairobi machine).
A list of Model objects is created, each with the specified preferences.
For each model, we apply Randomized Benchmarking with the corresponding parameters and sample the resulting quantum state.
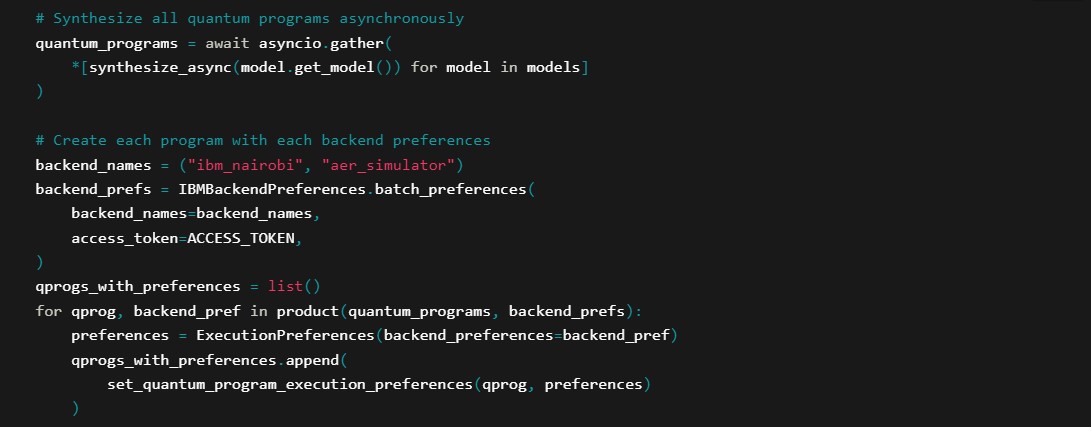
Program Synthesis
This asynchronous call converts our higher-level models into executable quantum code. Make sure to add your IBM ACCESS_TOKEN here.
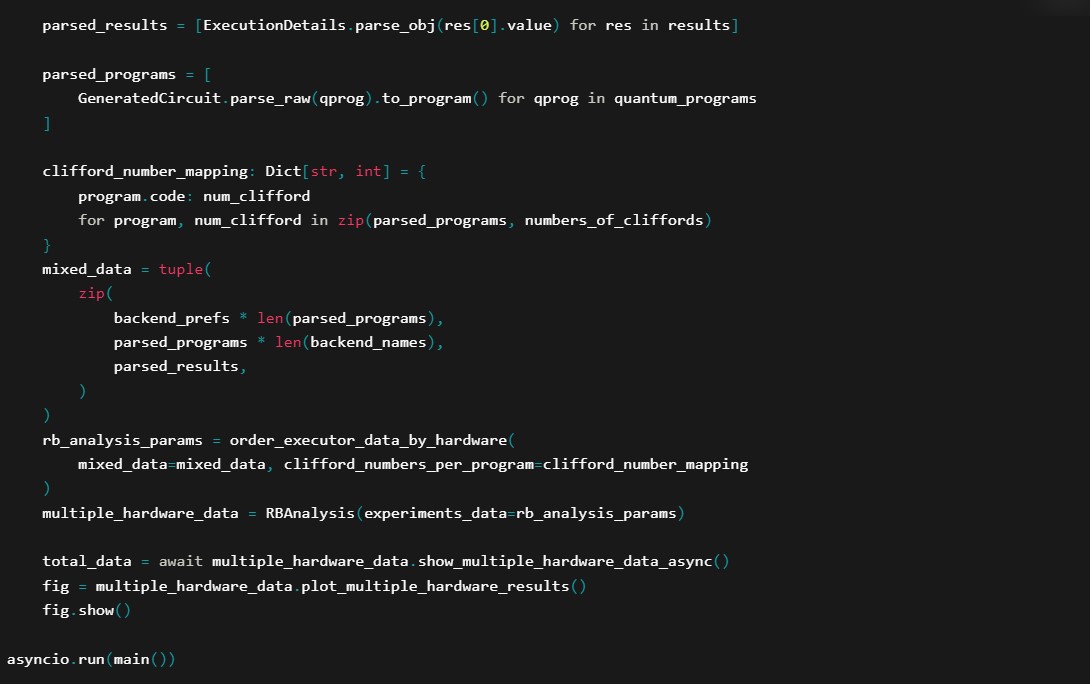
Execution

Parse and Analyze Results
The remaining code deals with parsing and analyzing the results of the quantum programs, eventually plotting these results. You can add additional plotting and analysis here.
After running the experiment, evaluate the following questions:
- What metrics did this benchmarking technique give us?
- What other benchmarking techniques should you run to understand the full picture of how this quantum device behaves?
- How does this metric change on larger quantum chips, or different hardware types (e.g. superconducting vs. trapped ions)?
- Replace the variable backend_names with your choice of hardware and test your hypothesis!
As quantum computing claims get more extraordinary, the need for benchmarking grows to provide extraordinary proof. Just as we wouldn’t buy a car that hasn't gone through a gauntlet of performance tests, we shouldn’t rely on quantum computers that haven’t been benchmarked for their capabilities.
And remember, corporations have incentives to choose the benchmarking techniques that give them the best numbers. Trust, but verify. Now you can benchmark on your own with Classiq!